MNIST Digit Recognizer
The same handwritten-digit classifier built four ways, from sklearn logistic regression (92%) through a NumPy from-scratch neural net (97%) to a PyTorch CNN (99%+). Deployed as a Streamlit 'draw a digit' demo.
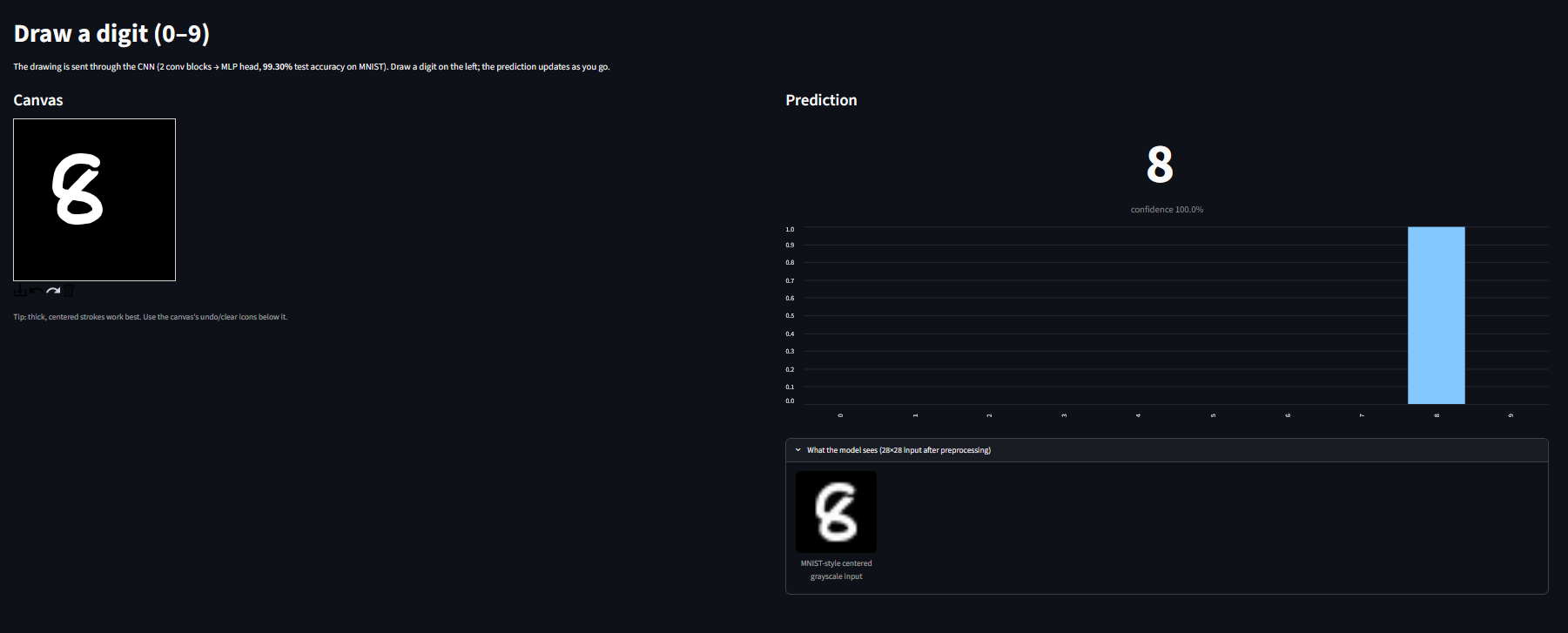
Overview
A learning ladder around one of the canonical computer-vision problems: classify handwritten digits 0 through 9 from the MNIST dataset. Built four times in increasing layers of abstraction, deployed as a “draw a digit and watch the model predict it” Streamlit app.
Why four implementations of the same network
The same classification problem at four levels of sophistication, each one teaching a different layer of the stack. The point isn’t the digits, it’s the ladder: a hand-coded backpropagation pass beside the equivalent thirty lines of PyTorch shows you exactly what the framework is doing for you, which makes every subsequent ML project faster to reason about.
The ladder
1. Logistic regression baseline (sklearn). Anchors what “good enough” looks like with linear models. Same API patterns as a previous tabular regression project, applied here to flattened pixels. Lands around 92% accuracy.
2. Two-layer neural network from scratch in NumPy. Forward pass, backward pass, manual stochastic gradient descent, every line written by hand. Lands around 97% accuracy. This is the phase where backpropagation stops being magic.
3. The same network in PyTorch. Re-implement using nn.Linear, optim.SGD, and DataLoader. Same accuracy as the NumPy version, in roughly 30 lines of code. After this, nn.Module and the training-loop idiom are muscle memory for everything that follows.
4. Convolutional network in PyTorch. Swap the dense layers for Conv2d and pooling. Accuracy jumps from 97% to 99%+. The “right inductive bias for images” stops being a slogan and becomes obvious.
5. Deployment. Wrap the trained CNN in a Streamlit app with a drawable canvas. Users draw a digit, the model predicts in real time.
Live: spadida-mnist-digit-recognizer.streamlit.app
Accuracy progression
| Implementation | Accuracy |
|---|---|
| Logistic regression (sklearn) | ~92% |
| 2-layer NN, NumPy from scratch | ~97% |
| 2-layer NN, PyTorch | ~97% |
| Convolutional NN, PyTorch | 99%+ |
The interesting jump isn’t from NumPy to PyTorch (same network, same accuracy, way less code). It’s from a dense network to a convolutional one, which is the lesson the whole project was set up to deliver.
What this taught me
Concepts that weren’t in the previous tabular project but became real here:
- Image data: pixels as features, normalization, batching.
- Classification metrics: accuracy, per-class precision and recall, the confusion matrix.
- Softmax with cross-entropy for multi-class outputs.
- One-hot encoding the target, not just the features.
- Neural network primitives: layers, activations (ReLU, sigmoid), losses.
- Backpropagation written by hand. Most valuable single exercise in the whole project.
- SGD and minibatches: batch size, epochs, learning rate.
- PyTorch idioms:
nn.Module,optim,DataLoader,Dataset, training loops. - Convolutional layers and pooling, and the reasons they work for image data.
- Regularization in deep learning: dropout, weight decay.
Stack
Python, NumPy, scikit-learn, PyTorch, Streamlit. Trained on CPU (each network takes 1 to 3 minutes on a modern laptop). Deployed on Streamlit Community Cloud.